
If you’re a software engineer or company using GitHub, safeguarding the data stored within GitHub is paramount.
The loss of valuable code repositories, critical project files, customer data, and more can have severe consequences that can impact your business operations.
In this blog, we’ll highlight the importance of prioritising content backup for your GitHub data. We’ll also share a range of manual backup strategies to help you effectively safeguard your data.
By implementing these strategies, you can mitigate the risks associated with data loss and ensure the safety and accessibility of your valuable information.
However, it’s important to recognise the limitations of manual data backup solutions. That’s why we’ll also explore how SaaS app protection solutions, such as BackupLABS, provide an effective and reliable alternative.
The importance of backing up your data from SaaS Apps such as GitHub
Here are the main reasons backing up your cloud data is a must:
- Legal Obligation: Data protection laws, such as GDPR, require regular backups to protect personal online data and ensure its security and integrity. While SOC 2 and ISO standards are not specifically mandated by law, many companies recognise their importance and choose to implement them to enhance data security and compliance
- Ransomware: Regular backups provide an additional layer of defence against ransomware, minimising the impact of attacks and facilitating data recovery
- Safeguarding against humans: Backing up your content from online apps helps mitigate the consequences of accidental deletion, file overwriting, malicious humans (eg disgruntled employees), or unintended modifications, allowing you to restore previous versions or retrieve deleted files
- Downtime: Proper backups ensure that critical data is readily available for recovery in the event of server failures, system crashes, or cybersecurity incidents, minimising downtime and reducing the impact on business operations
The limitations of backing up your data manually
While manual solutions like downloading the zip of your repository offer some level of data protection, it’s crucial to weigh the associated limitations, potential risks, and the impact on employee productivity.
- Employee cost and time: Manually downloading the repository zip requires dedicating employee time and resources. Depending on the size and complexity of the data, this process can be time-consuming, diverting valuable resources away from other important tasks
- Prone to human error: Manual data protection methods are more susceptible to human error. Mistakes such as incomplete or incorrect backups can occur during the manual downloading process, potentially compromising the integrity of your data
- Limited revision history: When downloading the repository zip file, it’s only going to capture the data at that moment. This means that previous revisions, comment history, and changes made over time may not be preserved. Retaining a comprehensive revision history can be crucial for tracking progress, identifying issues, and reverting changes if necessary
- Incomplete metadata: Manual downloading may not guarantee the preservation of all the metadata associated. This can include important information such as file properties, timestamps, authorship, and other contextual details. Maintaining metadata can be essential for proper data management, compliance, and future analysis
Automated backups like BackupLABS provide a more reliable and efficient way to preserve your data, ensuring comprehensive metadata, revision history, and ease of data restoration when needed.
How to back up your GitHub repositories
There are several methods you can use to protect your data stored on online apps.
Here are a few options:
Method 1: GitHub – Manually downloading your repository zip
The “download zip” option allows you to download the repository as a compressed zip file containing all the files and folders in the current state.
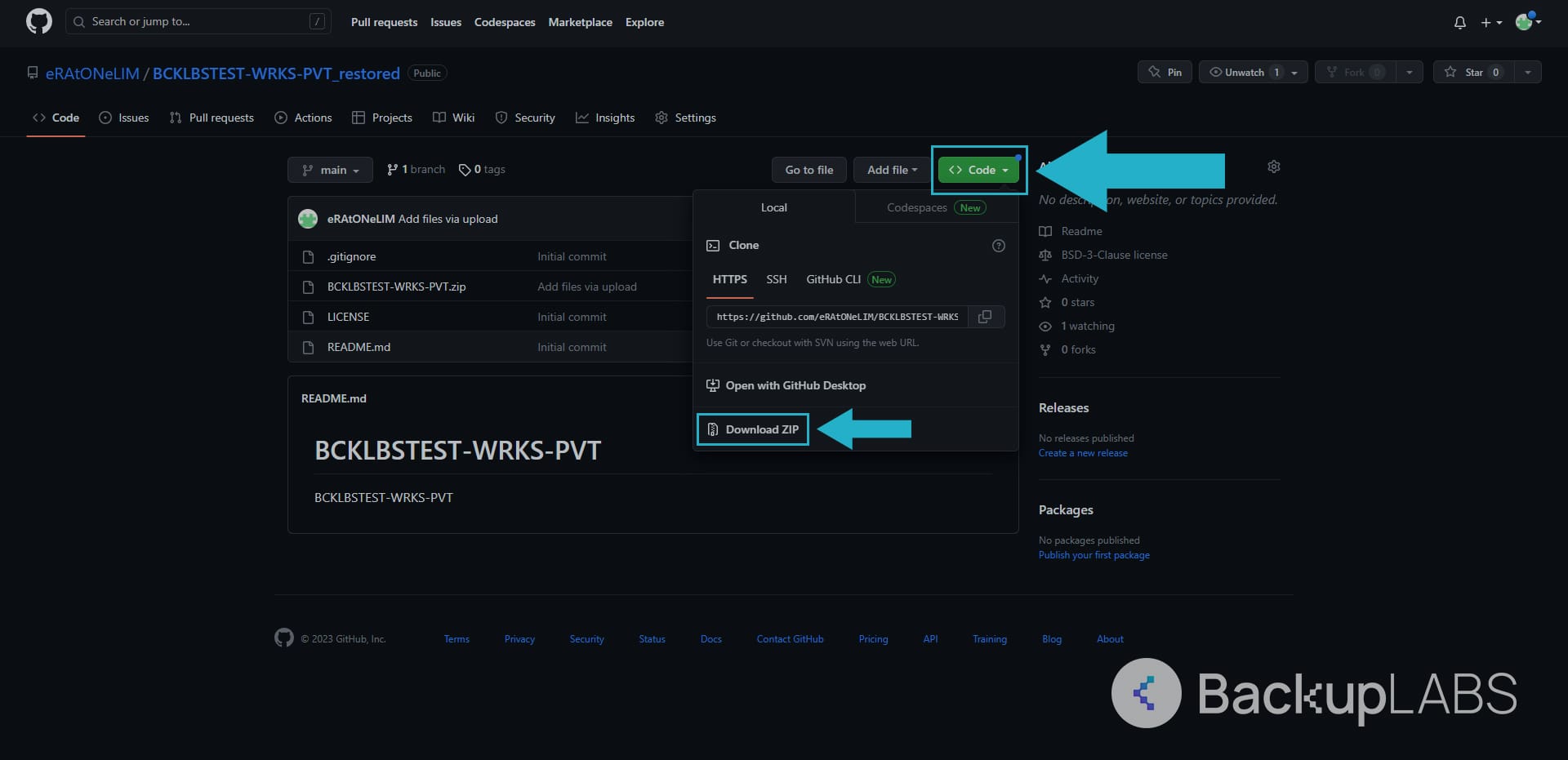
Downloading Repository Zip
- Go to the repository. Under the Code tab at the top, use the Code drop down and at the bottom, select Download Zip

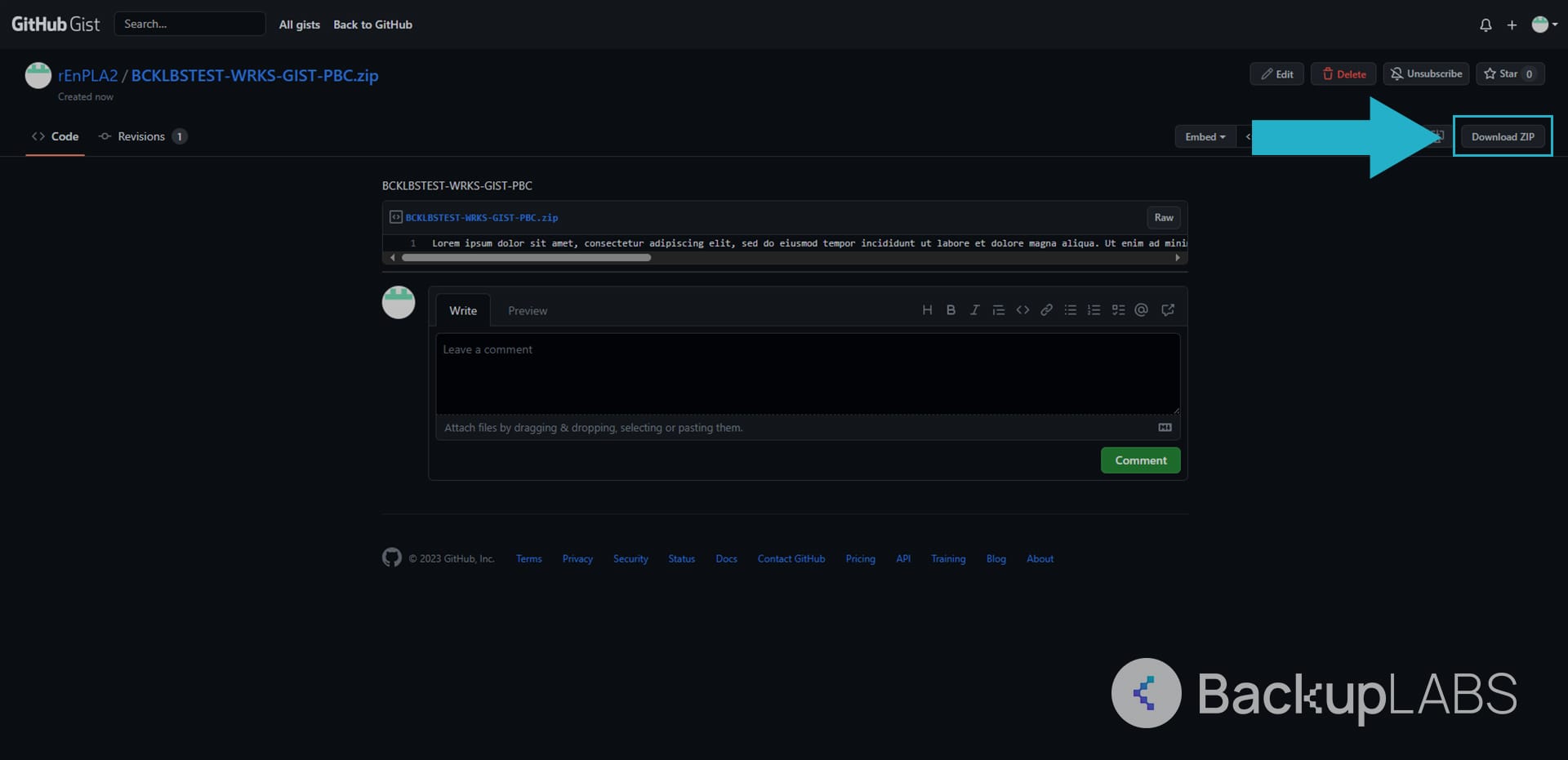
Downloading Gist Zip
- On your Gist, select Download ZIP in the top right of the page
Pros:
- Snapshot of current state: The downloaded zip file provides a snapshot of the repository’s current version, capturing all files and folders
- Offline access: Once downloaded, the zip file allows for offline access to the repository’s content
Cons:
- Limited version control: The zip file doesn’t retain the revision history of the repository, making it difficult to access previous versions or track changes over time
- Incomplete metadata: Comprehensive metadata associated with the repository, such as commit messages and timestamps, may not be preserved in the zip file
- Manual backup management: The responsibility of regularly downloading and storing updated zip files rests on the user, which can be prone to human error or oversight.
Method 2: Git Bash – Manually cloning a repository
- Open the repository on GitHub
- Click on the <> Code button at the top right of the repository page
- In the Clone section, copy the provided URL (HTTPS, SSH, or GitHub CLI) based on your preference
- Open Git Bash on your local computer
- Use the cd command to navigate to the desired location where you want to clone the repository. For example:
cd Documents/Projects/ - Execute the git clone command followed by the copied URL to start the cloning process:
$ git clone https://github.com/YOUR-USERNAME/YOUR-REPOSITORY - During the process, you will see progress updates, such as counting objects, compressing objects, and unpacking objects:
> $ git clone https://github.com/YOUR-USERNAME/YOUR-REPOSITORY > Cloning into `Spoon-Knife`... > remote: Counting objects: 10, done. > remote: Compressing objects: 100% (8/8), done. > remove: Total 10 (delta 1), reused 10 (delta 1) > Unpacking objects: 100% (10/10), done. - Wait for the cloning process to complete
Pros:
- Offline access: Once cloned, you can work with the repository offline, without the need for an internet connection
- Version control: Cloning preserves the entire revision history of the repository, enabling you to track changes and access previous versions of files
Cons:
- Limited backup functionality: Primarily focuses on creating a local copy of the code and does not provide comprehensive backup features
- Lack of metadata preservation: While cloning captures the content of the repository, it may not preserve all the metadata associated with it
- Manual update process: Requires manual actions to keep the local copy up to date with the latest changes in the repository, which can be time-consuming and prone to errors
- Single point of failure: Provides a single local copy, making it susceptible to data loss in case of hardware failures, accidents, or other unforeseen events
- Coding You will need coding literacy to understand and run the commands necessary
Method 3: Git Bundle – Manually cloning a repository
To use Git Bundle, create a bundle file, verify its content, and add it as the origin for a new repository. Here are the Git Bundle commands you can use:
- Create a Git Bundle:
git bundle create [-q | --quiet | --progress] [--version=] <file> <git-rev-list-args> - Verify a bundle:
git bundle verify [-q | --quiet] <file> - List the heads in a Git Bundle:
git bundle list-heads <file> [<refname>…] - Unbundle a Git Bundle:
git bundle unbundle [--progress] <file> [<refname>…]
Pros:
- Offline transfer: Allows offline transfer of repository branches as .pack files, enabling you to work with repositories without an internet connection
- Version control: Preserves the full history and revision information of the repository
- Open source: A popular open source solution made by GitHub members
Cons:
- Manual labor and monitoring: Requires manual effort and monitoring, leading to increased time consumption and potential human errors
- Limited comprehensive backup: Lacks automated scheduling, redundancy, and additional backup features found in dedicated backup solutions
- Potential for accidental modifications: Using Git Bundle manually may result in unintentional modifications to the repository due to the need for manual actions and management
- Complexity and limited support: Can be complex to work with, and support may be limited as it relies on the open-source community for assistance and updates
Method 4: BackupLABS – Automated GitHub backups
BackupLABS provides an effortless and automated solution for backing up your valuable GitHub repositories.
In just four simple steps, you can securely back up your data and enjoy easy access to your repositories at any time. Here’s how it works:
- Create a BackupLABS account
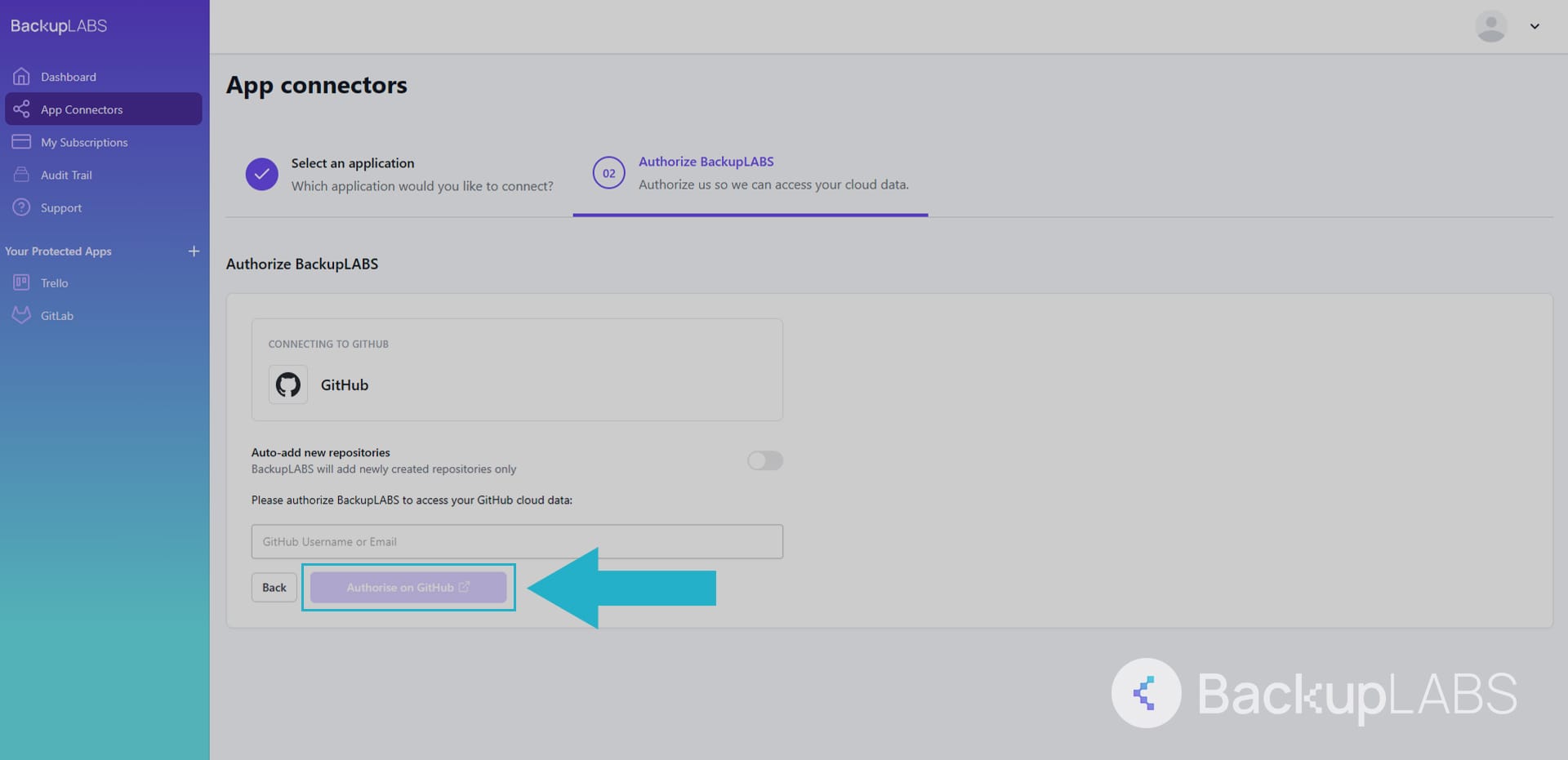
- Connect your GitHub account
- Choose what you want to backup
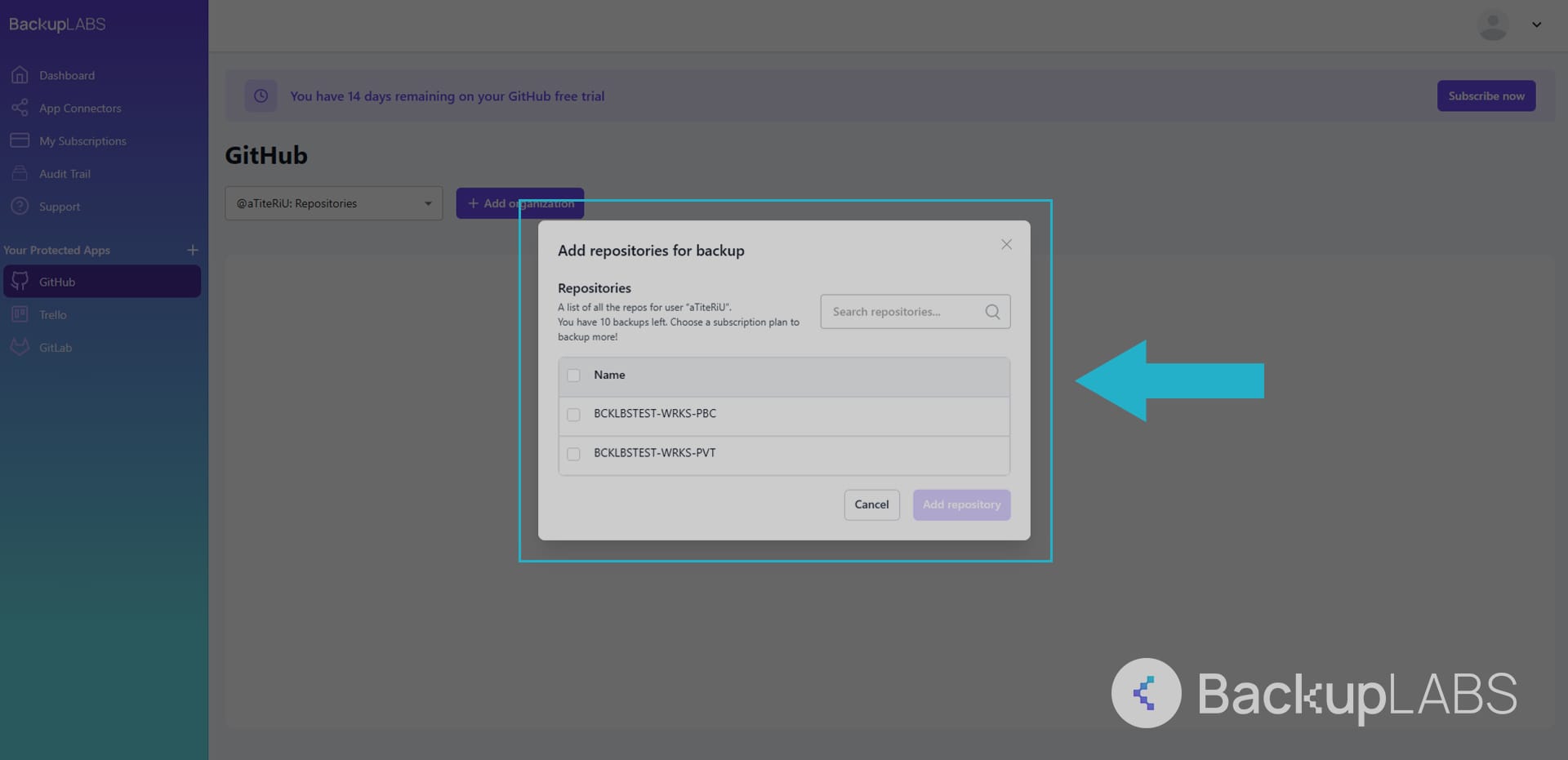
- Access your repositories and their revision history at any time
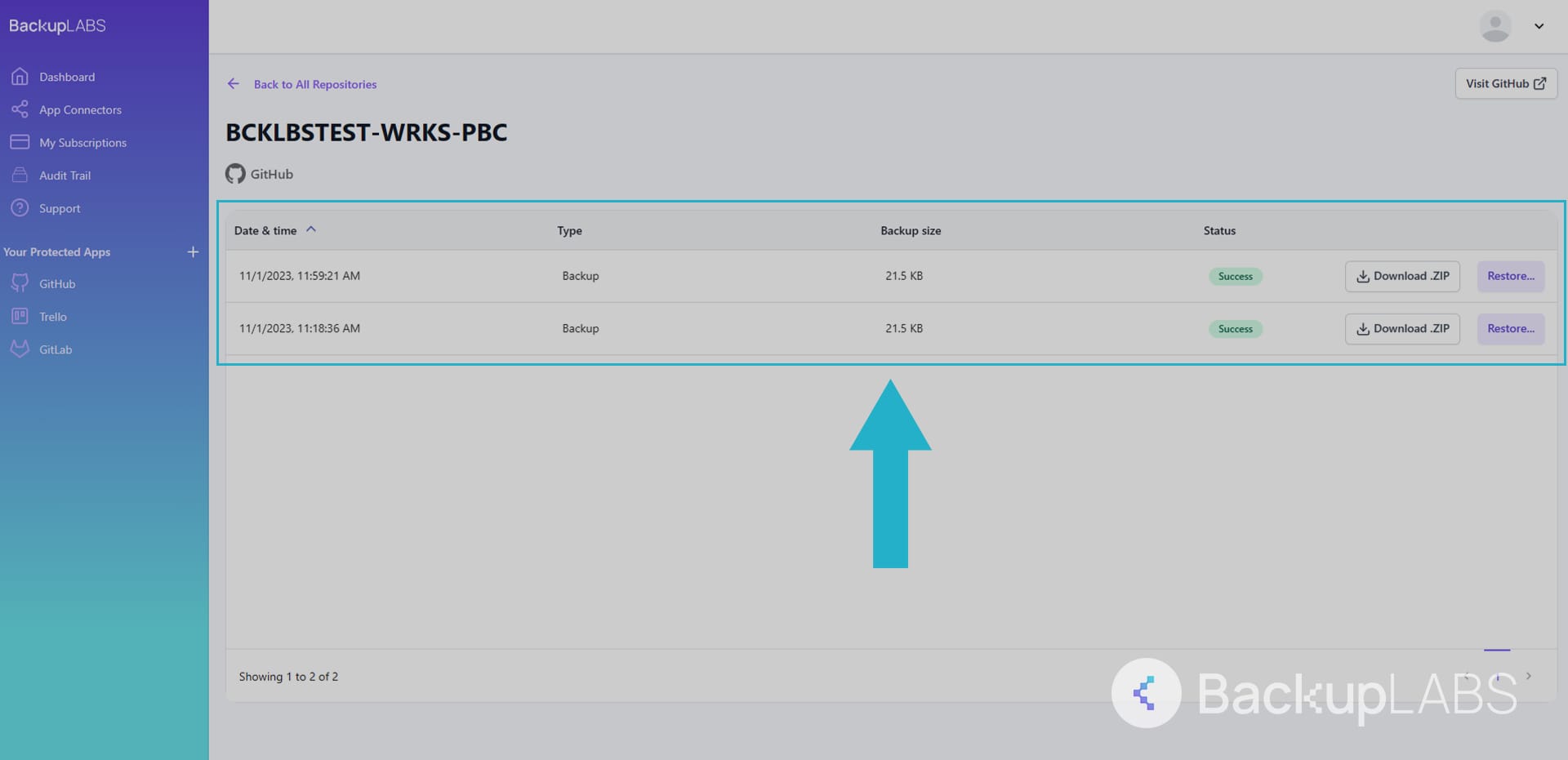
Why use BackupLABS as your backup solution?
With BackupLABS, you can enjoy a reliable and feature-rich backup solution while benefiting from excellent customer support and robust security.
BackupLABS offers a comprehensive backup solution with the following features:
- On-demand account level backups: Backup all your data anytime, without limitations
- Automated revision history: Retain and access iterations of your repositories
- Manual downloads: Privately download the zip files for your archive
- Account level restoration: Restore multiple files in bulk
- Create clones instantly: Use backups to create as many clones as you like
- Comprehensive metadata: Know your repositories retain as much data as possible
- Customer support: Dedicated customer support is available to assist you
- File renaming support: Optionally rename your restores with new names to easily identify
- Security alerts and notifications: Stay informed with security alerts and notifications
- Website security and encryption: BackupLABS ensures website privacy, security, and compliance with standards like SOC2 and ISO accreditation
Try BackupLABS for yourself, sign up for our 14-day free trial.

